Dossier: Software libre y código abierto:
experiencias innovadoras en bibliotecas y centros de información
Winisis multiformato de Unesco para el tratamiento de datos e información textual
Resumen: Se muestran y explican con ejemplos prácticos las posibilidades de tratamiento de datos e información textual que tiene el lenguaje de formateo de WINISIS de UNESCO al manipular cadenas y subcadenas de caracteres alfanuméricas no estructuradas o semiestructuradas, línea por línea, o párrafo por párrafo, de longitud fija o variable, especialmente en archivos lógicos de software (log), o provenientes de cualquier formato (Excel, Word, PDF u otro), convertidos a formato de texto plano norma ascii, para ser importados a través de programas en ISIS Pascal a CDS/ISIS. Se aplican expresiones y funciones (de cadena, numéricas o booleanas), expresiones, comandos, selectores de campos, subcampos y cadenas, para estructurar los datos y/o el texto, y obtener resultados de diseño de bases de datos, estadísticos y métricos.
Palabras clave: Winisis, Bases de datos, Formatos, Tratamiento de datos, Cadena de caracteres, Estadísticas.
Multiformatting WINISIS of UNESCO for data processing and textual information
Abstract: It is shown and explained with practical examples, the possibilities for data processing and textual information that has the formatting language WINISIS of UNESCO to manipulate strings and sub strings of alphanumeric characters unstructured or semi-structured, line by line or paragraph by paragraph, fixed length or variable, especially in logical software files (log), or from any format (Excel, Word, PDF or other), converted to plain text format standard ascii to be imported through programs in ISIS Pascal CDS / ISIS. expressions and functions (string, numeric or Boolean), expressions, commands, selectors fields, subfields and chains are applied to structure data and / or text and get results of design databases, statistical and metrical.
Keywords: Winisis, Databases, Formats, Data Processing, String, Statistics.
Introducción
En el medioambiente digital fluyen los datos y los textos a través de redes y bases de datos, en forma de cadenas de caracteres (alfabéticas, numéricas alfanuméricas y símbolos de código ASCII) provenientes del lenguaje natural o codificado del ser humano o autómatas creados por él, de dos tipos: lineales (tipo Excel o archivos lógicos) y en bloques de texto (párrafos de procesadores de texto o texto plano sin formato) (Rajasekharan y Nafala, 2007a). El lenguaje de formateo de Winisis permite manipular estas cadenas de caracteres para transformar texto o datos no estructurados o semiestructurados para obtener una estructura adecuada en el diseño de bases de datos, generación de estadísticas y aplicaciones métricas. El texto lineal es generalmente de longitud fija o semivariable, en tanto que el de bloque de texto es de longitud variable. Como el principio de la informática en sistemas integrales es que datos o texto digital no se deben digitar nuevamente (Chernii, 1977, p. 2) sino exportarse o modificarse de un formato a otro, para almacenar los datos en Winisis se recurre al proceso de importación por medio de programación en ISIS Pascal (Spinak, 1995) (dialecto desarrollado en MicroIsis, versión para MS-DOS), línea por línea o párrafo por párrafo, previa conversión a la norma ascii de texto plano, aun cuando puede ejecutarse en otros softwares que generen archivos ISO 2709, o Comma Delimited Values (CSV). Para resumir la importancia del tratamiento de datos, se ratificará lo que se plantea en el dossier big data de Telos: “bastan 140 caracteres y cinco segundos para acabar con el prestigio, la marca y el futuro de una empresa” (Rodríguez y Marauri, 2013, p. 99).
Aún mayor trascendencia tiene el tratamiento de cadenas de caracteres en el campo de la investigación cualitativa:
La naturaleza de los datos manejados en la investigación vendrá condicionada por las técnicas o instrumentos utilizados para recogerlos y por los presupuestos teóricos, filosóficos o metodológicos según los cuales desarrolla el proceso de investigación. Dado que en la investigación cualitativa se suelen utilizar la entrevista, la observación, las preguntas abiertas presentadas mediante cuestionarios, los diarios, etc. El tipo de datos recogidos suele venir expresado en forma de cadenas verbales y no mediante valores numéricos (…) De ahí que la mayor parte de los datos que son recogidos en el curso de las investigaciones cualitativas posean como una de sus características más conocidas la de ser expresados en forma de textos. Se trata de datos que reflejan la comprensión de los procesos y las situaciones por parte de los propios participantes en los contextos estudiados (Rodríguez et al., 1996, p. 23).
Problematización
Por mucho tiempo el desconocimiento o conocimiento parcial de CDS/ISIS ha dado lugar a mitos e imprecisiones respecto de sus características y potencialidades. Uno de ellos es que por ser definido como un gestor de bases de datos textuales “no numéricas” no puede realizar cálculos y estadísticas básicas por sí solo.
Y aunque existen varios artículos que desmienten esta supuesta limitación, desde la versión original de Microisis (en ambiente MS-DOS) es relevante que la programadora Gilda Ascencio, dedicada actualmente al desarrollo del programa ABCD, en 1992 presentó la ponencia “Propuesta de una estructura de bases de datos para almacenamiento y recuperación de información estadística en Microsis”, en las II Jornadas Nacionales y I Latinoamericanas y del Caribe sobre Microisis. Se plantea ya en ese tiempo –sin pretender transformar al sistema en un programa estadístico dado que no fue concebido para ello– el interrogante
“¿Han encontrado Uds. algún sistema que permita almacenar y recuperar información estadística conjuntamente con textos que analicen los resultados, y que, a su vez, facilite la recuperación de la información ingresada mediante estrategias de búsqueda por lógica booleana y permita la transferencia de información a otros programas estadísticos para un manejo numérico?” Frente a la respuesta negativa, planteó un desafío: “Entonces, ¿por qué no hacerlo en Microisis?”. Para ello propone cuatro tipos de registros: definición de variables y cuadros, utilizando las etiquetas numéricas de identificación de campos, y la división en ocurrencias y subcampos para definir filas, columnas y valores aritméticos.
Entonces, para ubicar el valor de una celda dentro de un cuadro estadístico, bastará con ubicar el tag del campo, el número de ocurrencia y el código de sub-campo utilizado para almacenar la información.
(…)
Entonces, si es posible almacenar la información estadística en un registro Microisis y tener acceso a cada una de las celdas, podemos realizar cualquier tratamiento con la información: extraer una fila o columna o celda específica de un cuadro o grupo de ellos, generar cuadros resumen, elaborar cuadros comparativos a nivel de filas o columnas y exportar la información a hojas de cálculo (Lotus, etc.) u otros sistemas estadísticos o programas especializados en gráficos. También es posible importar cuadros desde otros sistemas para almacenarlos en nuestra base de datos Microisis.
(…)
Lo importante es desarrollar el algoritmo que transforme las coordenadas de una celda (fila, columna) a su representación en número de etiqueta, número de ocurrencia y delimitador de subcampo (Ascencio, 1992, v.2, pp. 35-41).
Para aplicaciones más complejas y sofisticadas, UNESCO desarrolló el paquete para análisis estadístico IDAMS utilizado en combinación con CDS/ISIS, plenamente compatible. http://portal.unesco.org/ci/en/files/25633/12155219637ManualR13S.pdf/ManualR13S.pdf (UNESCO, 2008). “Hay un programa separado, WinIDIS, el cual prepara la descripción de los datos y hace la transferencia de los mismos entre IDAMS y CDS/ISIS”.
Posteriormente, con la versión de Winisis en ambiente Windows se potenció el programa con su ambiente gráfico y la implementación de variables, expresiones y funciones numéricas, que son las que exponemos en los ejemplos a continuación, en el contexto del poderoso lenguaje de formateo que posee el software. De esta manera, se ratifica su vigencia, versatilidad, adaptabilidad y complementariedad con otros softwares, que le han permitido ser una herramienta imprescindible por más de 30 años.
Análisis y ejemplos de formateo lineal
Como resultado de la importación lineal, la información generada se almacena en un solo campo de datos de Winisis, respetando su sintaxis, orden y ubicación, así como la longitud de sus datos, con preservación del texto original. Todas las referencias al uso de los componentes del lenguaje de formateo –como comandos, expresiones, funciones, etc.– tienen como fuente bibliográfica el capítulo 8 del Manual de Referencia de Winisis 1-5, “El lenguaje de Formato de Winisis”, en idioma español e irán entrecomilladas (UNESCO, 2004, pp.135-188).
También será recurrente el uso de una regla de medición desarrollada en el propio lenguaje de formateo, para apreciar de mejor forma el tratamiento de cadenas y subcadenas de caracteres, como se muestra en la primera base de datos a analizar, WCTRL, generada por Winisis para el control del proceso de edición y mantención de sus bases.
Base de Datos WCTRL
Es una base de datos de gestión que controla los procesos de edición en Winisis, como creación, actualización, borrado, reactivación de registros o actualización de archivo invertido y cambios globales realizados por los operadores. Resulta ser de gran utilidad para los administradores de procesos técnicos y de la red de datos, ya que se tiene como proveedor de información al archivo lógico que genera Winisis. El nombre y localización de este archivo se declara en el parámetro 939 del archivo syspar.par o de configuración de Winisis (Adams, 2005), que importa archivos en texto plano (Ascii), línea por línea o párrafo por párrafo, y crea con cada uno de ellos un registro en la base de datos –sin tener que digitar el texto– de forma automática a CDS/ISIS, con un programa en ISIS Pascal desde la versión para MS-DOS,
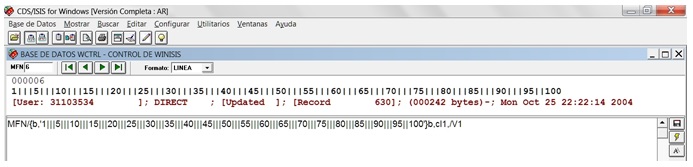
Se puede apreciar en la imagen la pantalla dividida debajo del indicador automático de registro (MFN 6), las teclas de desplazamiento y el nombre del formato utilizado (LINEA), los elementos de visualización en la parte superior y el formato que genera la regla ya mencionada en negrita (cadena de caracteres generada por un literal incondicional entre comillas simples), para mostrar a continuación los datos de la línea original en rojo, almacenados en el campo de datos 1 (V1) de Winisis, que contiene en total 18.335 registros similares como se muestra en el margen inferior derecho de la pantalla (MAX: 18335).
Un primer problema a resolver con los datos es que los encabezamientos o contenidos de subcadenas están en inglés (User, Update, Record, etc.), y la fecha con nombre de días y meses en inglés (en orden MMDDAA), los cuales deben ser normalizados al español (DDMMAA). Estos cambios de sintaxis serán tratados con el lenguaje de formateo gradualmente hasta lograrlo.
El formato estándar de Winisis, que tiene el mismo nombre de la base de datos (WCTRL), se mantendrá compatible con las versiones para Windows y Ms-dos.
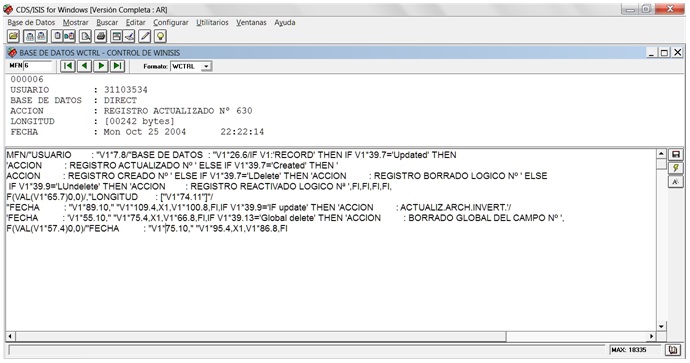
En esta imagen se puede observar que en el área de visualización de datos, los encabezamientos o textos de las subcadenas han sido “traducidos” por el formato, comenzando por USUARIO: (User) cuyo código numérico 31103534 individualiza al computador desde el cual se editó el registro, o utilizando encabezamientos no existentes en la línea original, como BASE DE DATOS: (DIREC), ACCIÓN: (REGISTRO ACTUALIZADO Nº 630, del original Update), LONGITUD: ([00242 bytes]) y FECHA: (Mon Oct 25 2004 22:22:14) aún en inglés, que incluye hora a continuación, omitiendo el encabezamiento. La estructura visualmente simula la presentación de 5 campos de datos que no son tales, puesto que la cadena completa está almacenada en el campo 1, y los segmentos o subcadenas se muestran con el uso de comandos inicio/longitud del formato (*inicio.longitud = V1*7.8), combinado con el comando IF, que implementa formatos sensibles al contexto, capaces de producir resultados variables dependiendo del contenido del registro, especialmente cuando las subcadenas que tratamos tienen longitud variable y, por lo tanto, también varían su localización de inicio y fin en la cadena, lo que constituye el segundo problema de tratamiento de datos e información.
*inicio indica la posición del primer carácter a ser extraído del campo o subcampo (la posición de los caracteres se cuenta a partir de cero, es decir el primer carácter ocupa la posición cero). Si se omite *inicio CDS/ISIS lo asume como cero.
.longitud indica el número de caracteres a extraer del campo o subcampo. Si se omite el valor de .longitud CDS/ISIS asume su valor hasta la longitud total del campo o subcampo desde la posición *inicio. (UNESCO, 2004; Molino, 1990).
En tanto que el comando IF, se codifica de la siguiente manera:
IF condición THEN formato-1 ELSE formato-2 FI
donde:
condición es una expresión booleana definida de acuerdo con lo indicado bajo "Expresiones booleanas";
formato-1 es un formato de CDS/ISIS que será ejecutado si, y sólo si la expresión booleana es Verdadero;
formato-2 es un formato de CDS/ISIS que será ejecutado si, y sólo si la expresión booleana es Falso. (UNESCO, 2004; Buxton y Hopkinson, 2001 ).
Se ve que V1*26.6 indica la localización precisa del nombre de la base de datos DIRECT, en tanto que para visualizar la ACCIÓN en español –dependiendo de la sintaxis de esta– se deben representar en el formato una sucesión de comandos IF anidados, siempre y cuando que esté presente la subcadena RECORD en la línea:
IF V1:'RECORD' THEN IF V1*39.7='Updated' THEN
'ACCION : REGISTRO ACTUALIZADO Nº ' ELSE IF V1*39.7='Created' THEN '
ACCION : REGISTRO CREADO Nº ' ELSE IF V1*39.7='LDelete' THEN
'ACCION : REGISTRO BORRADO LOGICO Nº ' ELSE
IF V1*39.9='LUndelete' THEN
'ACCION : REGISTRO REACTIVADO LOGICO Nª ',FI,FI,FI,FI,
Es notorio que en el último comando IF de la acción varía la longitud de LUndelete (en azul) al aplicar el comando inicio/longitud, de V1*39.7 que tenía V1*39.9, al contener la subcadena dos caracteres más que las anteriores (Updated, Created, LDelete).
En la siguiente imagen –mitad superior de la pantalla dividida del formato FWIN– se observan cambios en los encabezamientos del registro e incorporación de nueva semántica, y con ello culmina el proceso de conversión de la fecha al español.
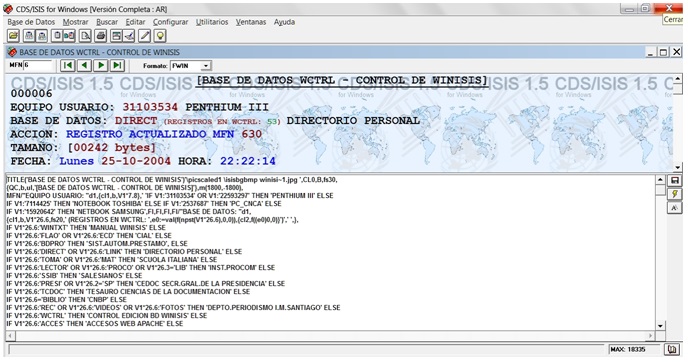
Se modifica el encabezamiento de usuario por EQUIPO USUARIO, se especifica el contenido del campo con el código en rojo seguido de la identificación del tipo de equipo PENTHIUM III. En tanto en el encabezamiento BASE DE DATOS, el nombre en rojo tiene el valor total de registros contenidos en WCTRL en verde y entre paréntesis (53, si se aplica combinadamente la función VAL y NPST) (CNEA, 1998; Zbiniew, 2001; UNESCO, 2004), seguido de la especificación del tipo de función DIRECTORIO PERSONAL, cuyas variables en el formato INSTIT se presentan a continuación:
IF V1*26.6:'WINTXT' THEN 'MANUAL WINISIS' ELSE
IF V1*26.6:'FLAO' OR V1*26.6:'ECD' THEN 'CIAL' ELSE
IF V1*26.6:'BDPRO' THEN 'SIST.AUTOM.PRESTAMO', ELSE
IF V1*26.6:'DIRECT' OR V1*26.6:'LINK' THEN 'DIRECTORIO PERSONAL' ELSE
IF V1*26.6:'TOMA' OR V1*26.6:'MAT' THEN 'SCUOLA ITALIANA' ELSE
IF V1*26.6:'LECTOR' OR V1*26.6:'PROCO' OR V1*26.3='LIB' THEN 'INST.PROCOM' ELSE
IF V1*26.6:'SSIB' THEN 'SALESIANOS' ELSE
IF V1*26.6:'PRESI' OR V1*26.2='SP' THEN 'CEDOC SECR.GRAL.DE LA PRESIDENCIA' ELSE
IF V1*26.6:'TCDOC' THEN 'TESAURO CIENCIAS DE LA DOCUMENTACION' ELSE
IF V1*26.6='BIBLIO' THEN 'CNBP' ELSE
IF V1*26.6:'REC' OR V1*26.6:'VIDEOS' OR V1*26.6:'FOTOS' THEN 'DEPTO.PERIODISMO I.M.SANTIAGO' ELSE
IF V1*26.6:'WCTRL' THEN 'CONTROL EDICION BD WINISIS' ELSE
IF V1*26.6:'ACCES' THEN 'ACCESOS WEB APACHE' ELSE
IF V1*26.6:'EQUIP' OR V1*26.6:'MHCM' THEN 'LICITACION HOSP.CALVO MACKENA' ELSE
IF V1*26.6:'MUDP' THEN 'PERIODISMO UNIV.DIEGO PORTALES' ELSE
IF V1*26.6:'NPROD' OR V1*26.6:'ANFOT' OR V1*26.6:'DCCP' THEN 'CHILECOMPRAS' ELSE
IF V1*26.6:'ADKI' THEN 'ADQUISICIONES' ELSE
IF V1*26.6:'PSM' THEN 'UNIV.SIMON BOLIVAR' ELSE
IF V1*26.6:'THES' THEN 'MACROTESAURO OCDE' ELSE
IF V1*26.6:'BASE' THEN 'ADMIN. BD GENISIS' ELSE
IF V1*26.6:'PRVB' THEN 'BD DE PROVERBIOS' ELSE
IF V1*26.6:'SPROF' THEN 'SERVICIOS PROFESIONALES HRV' ELSE
IF V1*26.3='BIB' OR V1*26.6:'AUDBIB' THEN 'UNESCO STGO.' ELSE
IF V1*26.6:'BUPLA' OR V1*26.6:'FACSO' OR V1*26.6:'PRUPLA' THEN 'UPLA' ELSE
IF V1*26.6:'OF' OR V1*26.6:'SREX' THEN 'CNCA' FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI/
Para demostrar el número de apuntadores de la base de datos, se utiliza la variable numérica e0 (que en Winisis va de e0 a e9), y combinadamente la función VAL, F y NPST como se ve en el siguiente segmento de formato:
e0:=val(f(npst(V1*26.6),0,0)
La función VAL, que devuelve el valor numérico de su argumento, la función F, que convierte un valor numérico a una cadena de caracteres, y la función NPST, que busca en el archivo inverso del diccionario de búsqueda el término definido por formato y devuelve el número de apuntadores (postings) del mismo –en el ejemplo (registros en WCTRL: 53)–. Para mostrar ese resultado sigue este otro segmento de formato:
{cl2,f((e0)0,0)}')',' ',}
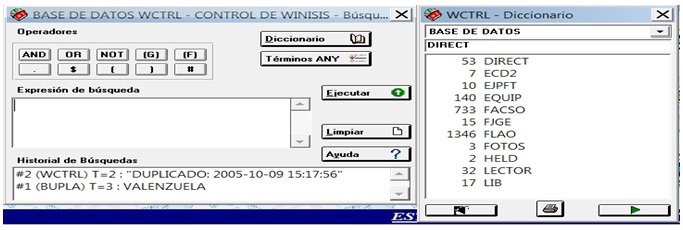
Se indica el diccionario con los 53 apuntadores de la base de datos DIRECT al inicio del listado:
El cambio más importante, sin embargo, es la conversión y españolización de la fecha, desde la cadena original, que traduce el día y modifica el orden de MMDDAA a AAMMDD separando la hora:
FECHA: Mon Oct 25 2004 22:22:14 [subcadena original]
FECHA: Lunes 25-10-2004 HORA: 22:22:14 [subcadena modificada por el formato]
Lo observado en la mitad inferior de la pantalla se logra con el siguiente segmento del formato FWIN, que a su vez llama a los formatos DIA (@DIA), @DDMMAA (día, mes, año) y HORA (@HORA), como puede apreciarse –la arroba debe anteceder siempre al nombre del formato–, se incorporan todos los formatos enlazados:
{cl0,'FECHA: ',d1},{cl1,b,{cl16,@DIA,}' ',@DDMMAA,{cl0,' HORA: '},{cl16,@HORA}
“Se pueden incluir formatos predefinidos en un formato mediante el uso de la función nombre, donde nombre es el nombre del formato a ser incluido. Este formato debe estar archivado en el directorio de la base de datos activa” (UNESCO, 2004, p.171).
FORMATO DIA:
IF V1:' Mon ' THEN 'Lunes' ELSE IF V1:' Tue ' THEN 'Martes' ELSE IF V1:' Wed ' THEN 'Miércoles' ELSE IF V1:' Thu ' THEN 'Jueves' ELSE IF V1:' Fri ' THEN 'Viernes' ELSE IF V1:' Sat ' THEN 'Sábado' ELSE IF V1:' Sun ' THEN 'Domingo' FI,FI,FI,FI,FI,FI,FI
Este formato traduce el nombre en inglés del día al español.
FORMATO AAMMDD:
IF V1:'RECORD' THEN V1*109.4'-',@MESNU,'-',v1*97.2, ELSE
IF V1:'IF ' THEN ,V1*75.4'-',@MESNU,'-'V1*63.2, ELSE
IF V1:'GLOBAL' THEN @GLOBF,FI,FI,FI
Este formato si se cumple la condición de presencia de la subcadena RECORD, IF, o GLOBAL, llama a los respectivos formatos (@MESNU, @GLOBF).
FORMATO MESNU:
IF V1:'Jan' then '01' ELSE IF V1:'Feb' then '02' ELSE IF V1:'MAR' THEN '03' ELSE IF V1:'APR' THEN '04' ELSE IF V1:'MAY' THEN '05' ELSE
IF V1:'JUN' THEN '06' ELSE IF V1:'JUL' THEN '07' ELSE IF V1:'AUG' THEN '08' ELSE IF V1:'SEP' THEN '09' ELSE IF V1:'OCT' THEN '10' ELSE
IF V1:'NOV' THEN '11' ELSE IF V1:'DEC' THEN '12',FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI
Este formato localiza la subcadena de nombre del mes en inglés (Jan, Feb, Mar, etc.) y la substituye por el número secuencial ascendente (01 a 12), correspondiente.
FORMATO GLOBF:
IF V1:'GLOBAL' THEN
IF VAL(V1*57.5)<10 AND V1*69.1=']' THEN V1*95.4 ,'-',@MESNU,'-',V1*83.2 ELSE
IF VAL(V1*57.5)<10 AND V1*67.1=']' THEN V1*93.4,'-',@MESNU,'-',V1*81.2 ELSE
IF VAL(V1*57.5)<10 AND V1*65.1=']' THEN V1*91.4,'-',@MESNU,'-',V1*79.2 ELSE
IF VAL(V1*57.5)<10 AND V1*67.1=']' THEN V1*94.4,'-',@MESNU,'-',V1*81.2 ELSE
IF VAL(V1*57.5)<10 AND V1*68.1=']' THEN V1*94.4,'-',@MESNU,'-',V1*82.2 ELSE
IF VAL(V1*57.5)<10 AND V1*73.1=']' THEN V1*99.4,'-',@MESNU,'-',V1*87.2 ELSE
IF VAL(V1*57.5)>9 AND VAL(V1*57.5)<100 AND V1*69.1=']' THEN V1*95.4,'-',@MESNU,'-',V1*83.2 ELSE
IF VAL(V1*57.5)>9 AND VAL(V1*57.5)<100 AND V1*66.1=']' THEN V1*92.4,'-',@MESNU,'-',V1*80.2 ELSE
IF VAL(V1*57.5)>9 AND VAL(V1*57.5)<100 AND V1*67.1=']' THEN V1*93.4,'-',@MESNU,'-',V1*81.2 ELSE
IF VAL(V1*57.5)>9 AND VAL(V1*57.5)<100 AND V1*68.1=']' THEN V1*94.4,'-',@MESNU,'-',V1*82.2 ELSE
IF VAL(V1*57.5)>9 AND VAL(V1*57.5)<100 AND V1*70.1=']' THEN V1*96.4,'-',@MESNU,'-',V1*84.2 ELSE
IF VAL(V1*57.5)>99 AND VAL(V1*57.5)<1000 AND V1*67.1=']' THEN V1*93.4,'-',@MESNU,'-',V1*81.2,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI,FI
En este formato se incluye la función VAL que devuelve el valor numérico de su argumento, lo que permite medir si el valor de la subcadena acotada con el comando inicio/longitud (V1*57.5) es mayor que 9 o 99 y (AND), la subcadena (V1*57.5) es menor que 100 (<100) o que 1000 y (AND); la subcadena final contiene el carácter ‘]’ o cierre de corchete en la posición inicio/longitud indicada, para mostrar, de cumplirse la condición, la subcadena requerida a mostrar con el comando inicio/longitud, el guion ‘-‘, y la llamada al formato @MESNU, seguido de guion ‘-‘.
Estas posiciones han sido medidas con la regla, de acuerdo a cómo se comportan los datos en la cadena almacenada en el campo 1 de los registros de la base de datos WCTRL.
Finalmente, se muestran las mediciones estadísticas con el formato ESTAD:
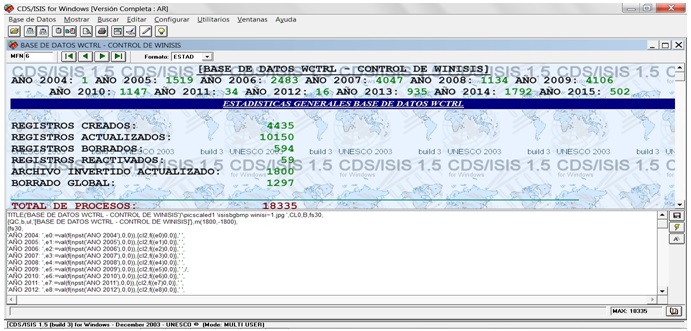
En las dos líneas superiores de la imagen, bajo el título, se presentan la cantidad de registros por año, en el período 2004 a 2015, almacenados en la base de datos, y más abajo el total por acción o proceso individual, para cerrar con el número total de procesos que alcanza a los 18.335 registros.
Analizaremos los fragmentos del formato ESTAD que muestran el efecto visual:
'AÑO 2004: ',e0:=val(f(npst('ANO 2004'),0,0)),{cl2,f((e0)0,0)},' ',
El formato pone el encabezamiento AÑO 2004: y almacena en la variable numérica e0 el valor (VAL), convirtiendo a caracteres el número de apuntadores o posting (f(npst) correspondientes a dicha cadena (‘ANO 2004’) en el diccionario. Muestra el valor almacenado en la variable 0 con {cl2,f((e0)0,0)}, y así sucesivamente cada año. Mostramos el diccionario:
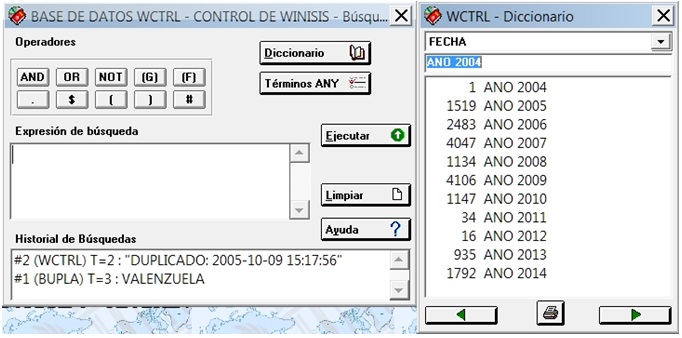
Las distintas acciones o procesos son visualizados para cada uno de ellos, con el segmento de formato:
'REGISTROS CREADOS: ',TAB(6200),e0:=val(f(npst('REGISTRO CREADO'),0,0)),{cl2,' ',f((e0)0,0)}/%
Aquí sólo varía para cada uno el literal de encabezamiento, el número de la variable (de e0 a e5), y el literal del nombre, que apunta al diccionario.
En el siguiente segmento, luego de la raya para la suma (en verde, cl6), el total de procesos se almacena en la variable numérica e6, que almacena sumando los valores parciales de e0 a e5 y entrega el valor total de la suma con la función F en rojo (cl1).
CL6,B,'_________________________________________________________________________________'/,
CL1,'TOTAL DE PROCESOS: ',TAB(6100),e6:=(e0+e1+e2+e3+e4+e5),' ',f((e6)0,0)/},
La integración de todos los formatos analizados entrega la siguiente pantalla:
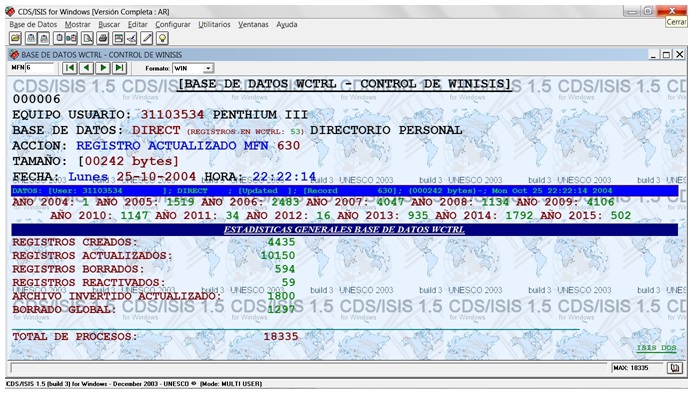
Complementariamente, se dirá que la Tabla de Definición de Campos (Field Definition Table = FDT) de la base de datos, aunque sólo consta de un campo de datos (el V1), incluye 5 campos en su estructura, con el objetivo de poder seleccionarlos como tales en la Tabla de Selección de Campos (Field Selection Table = FST), que crea el fichero inverso y el diccionario de búsqueda de acceso directo, para poder filtrar en éste la visualización de las claves de acceso por campos.
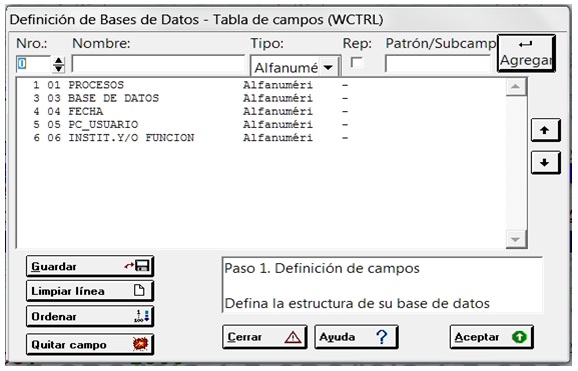
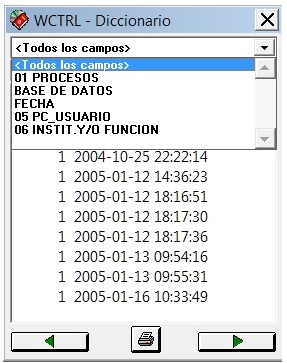
Las líneas que no tienen numeración en la ventana de selección de campos del diccionario se debe a que en la FST hacen referencia a llamados de formato (@formato), o a la aplicación directa del comando inicio/longitud, como mostraremos en las líneas de esta tabla a continuación:
1 0 IF V1:'RECORD' THEN IF V1*39.7='Updated' THEN 'REGISTRO ACTUALIZADO' ELSE IF V1*39.7='Created' THEN 'REGISTRO CREADO' ELSE IF
V1*39.7='LDelete' THEN 'REGISTRO BORRADO LOGICO' ELSE IF V1*39.9='LUndelete' THEN 'REGISTRO REACTIVADO LOGICO' ,FI,FI,FI,FI,FI
1 0 IF V1:'[IF UPDATE]' THEN 'ACTUALIZACION FICHERO INVERTIDO',FI,IF V1:'GLOBAL DELETE' THEN 'BORRADO GLOBAL',FI
3 0 v1*26.6/
4 0 @AAMMDD,' ',@HORA/,IF npst(@AAMMDD,' ',@HORA)>1 THEN 'DUPLICADOS'/'DUPLICADO: ',@AAMMDD,' ',@HORA/,FI
4 0 'ANO ',@AA
5 0 IF V1:'31103534' OR V1:'22593297' THEN 'PENTHIUM III' ELSE IF V1:'7114425' THEN 'NOTEBOOK TOSHIBA' ELSE IF V1:'2537687' THEN
'PC_CNCA' ELSE IF V1:'15920642' THEN 'NETBOOK SAMSUNG',FI,FI,FI,FI
6 0 @INSTIT
Se destaca en azul la línea de la FST correspondiente al campo 4, pues luego de incorporar al diccionario el año, mes, día y hora, pone la condición de que si su valor es mayor que 1, coloque la cadena de caracteres o literal incondicional ‘DUPLICADOS’ de forma genérica, y luego individual para cada duplicado, para detectar este error en la importación de registros.
Base de datos Acces
Base de Datos de Gestión que controla los accesos a Bases de Datos GENISIS de uso público en Internet (2003-2007) que utiliza el archivo de registros lógicos del Servidor APACHE (acces.log).
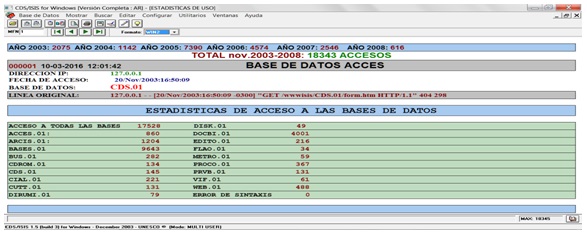
Archivo acces.log de apache, visualizado con ztreewin:
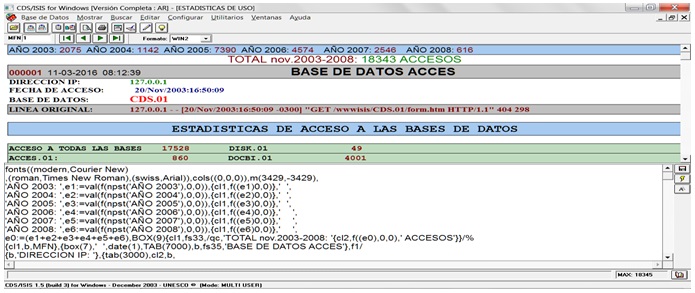
Se da a conocer la división de pantalla en Winisis, para mostrar el formato y su efecto visual, que permite diseñar y modificar interactivamente un formato. Al margen derecho, de la parte media inferior de la pantalla visualizamos 3 botones:
- 1. El de la letra A con sombra permite activar una ventana para seleccionar/modificar la fuente, su estilo y tamaño.
- 2. La del rayo permite activar temporalmente el formato modificado, para detectar su corrección o errores de sintaxis si los hubiere.
- 3. El del diskette permite grabar el formato modificado en forma permanente. Explicaremos las líneas de formato de forma seccionada e interactiva para su mayor comprensión.
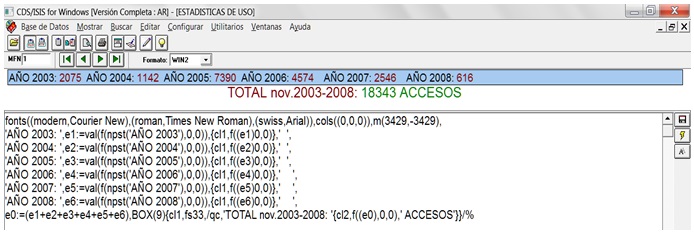
La primera línea del formato define las familias, tipos de letras y caracteres a utilizar, paleta de colores y márgenes (Buxton y Hopkinson, 2001; CNEA, 1992).
fonts((modern,Courier New),(roman,Times New Roman),(swiss,Arial)),cols((0,0,0)),m(3429,-3429)
Las cuatro líneas siguientes definen los literales incondicionales de AÑO (desde el 2003 a 2008), con comillas simples para cada subcadena de caracteres (‘AÑO 2003’, etc.), el almacenamiento en sus correspondientes variables numéricas (desde e1 a e6 para cada año), del valor del número de apuntadores (postings) en el diccionario para la cadena de caracteres AÑO (2003 a 2008), sin decimales:
e1:=val(f(npst('AÑO 2003'),0,0)),
Así como las indicaciones de visualización entre paréntesis de llave ({ }) en color rojo (cl1) de cada variable numérica sin decimales, con un literal incondicional (‘ ‘) que inserta espaciado entre números de cada línea:
{cl1,f((e1)0,0)},' ',
La línea final:
e0:=(e1+e2+e3+e4+e5+e6),BOX(9){cl1,fs33,/qc,'TOTAL nov.2003-2008: '{cl2,f((e0),0,0),' ACCESOS'}}/%
Almacena la suma de las variables numéricas individuales para cada año en la variable e0, en una caja en color celeste (BOX(9)) , define en una llave el color rojo ( {cl1 ) para caracteres de 33 puntos ( fs33 ), y en la línea siguiente inserta con centrado ( /qc, ) un texto literal incondicional ( 'TOTAL nov.2003-2008: ' ), para luego en un paréntesis de llave a continuación, en color verde ( {cl2 ), insertar y visualizar el valor numérico de la variable e0 , con un post literal incondicional 'ACCESOS' , cerrar ambas llaves y cambiar de línea (}}/%).
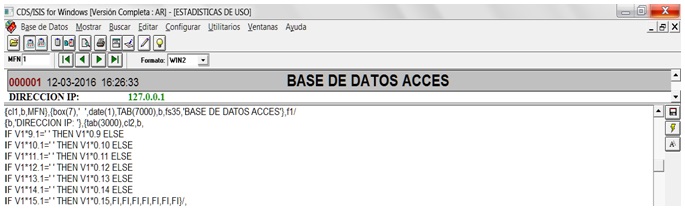
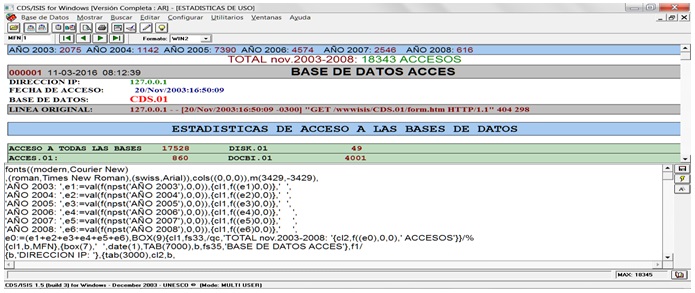
En el siguiente segmento del formato WIN2:
Abre paréntesis de llave ( { ), declara color rojo de caracteres en negrita ( cl1,b, ) para mostrar el MFN con sus seis dígitos, dentro de una caja en color gris ( box(7) ), realiza un espaciado con literal de un espacio en blanco entre comas ( ,‘ ‘, , declarando fecha y hora ( date(1) ), tabula 7000 puntos ( ,TAB(7000) ) y en negrita con 35 puntos ( ,b,fs35, ) despliega literal ‘BASE DE DATOS ACCES’ , cerrando con llave ( } ) y cambiando a la fuente 1 ( f1 ) y de línea ( /, ). Luego, abre llave ( { ) y en negrita ( b, ) muestra literal ‘DIRECCION IP: ‘ , cerrando y abriendo llave ( },{ ), tabulando 3000 puntos ( tab(3000) ) con color verde en negrita ( cl2,b, ). Debido a la longitud variable de la IP se utiliza el comando IF anidado para desplegar el formato de acuerdo a la posición y longitud donde se encuentra el carácter espacio en blanco que delimita el fin de la subcadena y es un valor constante, para desplegar la IP al cumplirse su condición lógica entre las columnas 10 a 15. Ejemplo: IF V1*9.1=' ' THEN V1*0.9 ELSE IF V1*10.1=' ' THEN V1*0.10 ELSE (…), etc. Lo cual quiere decir, SI ( IF ) en el campo V1, desde la posición columna 9 ( *9 ) hay un carácter igual a espacio en blanco ( .1=’ ‘ ), LUEGO ( THEN ), muestra los 9 caracteres del campo 1 desde la posición 0 ( V1*0.9 ), SI NO (ELSE) SI ( IF ) en el campo V1 , desde la posición columna 10 ( *10 ) hay un carácter igual a espacio en blanco ( .1=’ ‘ ), LUEGO ( THEN ), muestra los 10 caracteres del campo 1 desde la posición 0 ( V1*0.10 ), y así sucesivamente hasta completar los siete comandos IF anidados que terminan con el fin de sus condiciones lógicas ( ,FI,FI,FI,FI,FI,FI,FI}/, ), cierre del paréntesis de llave y cambio de línea.
Conclusiones
Con los ejemplos mostrados y explicados detalladamente, confirmamos que Winisis es una herramienta poderosa y eficiente para el tratamiento de cadenas y subcadenas de caracteres y texto, con su lenguaje de formateo interactivo e integral, que actúa combinadamente en las entidades básicas de sus bases de datos: tablas de definición y selección de campos, diccionario de búsqueda y recuperación de información, y formatos de impresión, validación, visualización y exportación de datos, tanto desde el punto de vista de la sintaxis como de la semántica, potenciando la codificación y decodificación de datos e información.
También se destaca que el ámbito de universos temáticos es ilimitado para el diseño e implementación de sus bases de datos y que no se limitan sólo al bibliográfico y de carácter textual no numérico, ya que pueden aportar a las metrías y estadísticas básicas del contexto informativo documental interactuando en el proceso de intercambio de información y datos con cualquier otro programa computacional. Por esta razón es conocida su protagónica presencia en Greenstone, ABCD, (Rajasekhara y Nafala, 2007b) Marco Polo, PMB, Koha, etc. Resulta también sorprendente que haya sido un programa utilizado para el desarrollo de sistemas expertos en Bulgaria hace más de 30 años, y también en inteligencia artificial para el reconocimiento de voz, más recientemente, gracias a la versatilidad de sus bases de datos. (Neelameghann y Lalitha, 2011).
Es digno de destacar, por otra parte, la supervivencia activa de este programa liberado por la UNESCO en 1985, con el apoyo decidido de otros organismos internacionales de ONU, en particular BIREME, fuera del ámbito comercial y de mercado, cuya comunidad de usuarios por décadas ha demostrado el valor de la cooperación y solidaridad en función de la investigación y el desarrollo, en forma especial en los países y regiones menos favorecidas del planeta.
Por estas razones, resulta una herramienta insustituible para la docencia y formación profesional de estudiantes de pre y postgrado, especialmente de periodistas, bibliotecólogos, y estudiosos de las ciencias sociales en general, así como de cualquier ciencia que requiera del tratamiento informativo documental, para la gestión de datos, información y conocimiento.
La dificultad de ser compatible con Windows sólo hasta la versión 7, es resuelta con el uso de Virtual Box Oracle u otros motores emuladores de sistemas operativos de 32 bits (Spinak, 2013).
Referencias
Adams, W. (2005). Parámetros del Syspar.par y Base.exp en castellano. Compilación de wenkeadam@yahoo.com.
Argentina. Presidencia. Comisión Nacional de Energía Atómica [CNEA] (1992). Actas II Jornadas Nacionales y I Latinoamericanas y del Caribe sobre MicroIsis, Buenos Aires, 2t. http://catalogosuba.sisbi.uba.ar/vufind/Record/http%253A%252F%252Fwww.sisbi.uba.ar%252Flibros%252FABB00002056/Description#tabnav
Argentina. Presidencia. Comisión Nacional de Energía Atómica [CNEA] (1998). Manual para instructores de Winisis, Buenos Aires.
Ascencio, G. (1992). Propuesta de una estructura de bases de datos para almacenamiento y recuperación de información estadística en Microsis. En II Jornadas Nacionales y I Latinoamericanas y del Caribe sobre Microisis, vol. 2. (pp. 35-41). Buenos Aires.
Buxton, A., y Hopkinson, A. (2001). CDS/ISIS for Windows Handbook. París: UNESCO/CI.
Chernii, A. I. (1977). Sistemas Integrales de Información (La Habana), Instituto de Documentación e Información Científica y Técnica, Academia de Ciencias de Cuba.
Molino, E. (1990). Manual de referencia Mini-micro CDS/ISIS (versión 2.3). UNESCO, México.
Neelameghan, A., y Lalitha, S. K. (2011). English-Tamil Bilingual Thesaurus Hyperlinked to an Online Tamil-English Lexicon to Support Classical Tamil Studies – Application of WINISIS and GSDL. Information Studies , 17(4), 225-242
Rajasekharan, K. y Nafala, K. M. (2007a). Converting Winisis Database into Access or Excel Database. Thrissur: India.
Rajasekharan, K. y Nafala, K. M. (2007b). Creating a Greenstone Digital Library with Winisis Database. Thrissur: India.
Rodríguez, M. M., y Marauri, I. (2013). El control de la reputación on_line para prevenir y gestionar una crisis. En TELOS 95 Dossier Big Data, Cuadernos de Comunicación en innovación, Fundación Telefónica, junio-septiembre 2013. Recuperado de https://telos.fundaciontelefonica.com/url-direct/pdf-generator?tipoContenido=articuloTelos&idContenido=2013062110000003&idioma=es
Rodríguez, G. et al. (1996). Metodología de la Investigación Cualitativa. Granada: Gran Aljibe
Spinak, E. (1995). Manual de programación CDS/ISIS Pascal. España: CSIC.
Spinak, E. (2013). Instalación de WinIsis en Windows 8 (64 bits) usando Virtual Box Oracle.
UNESCO (2004). Winisis Manual de Referencia (Versión 1.5). España: CSIC, CINDOC.
UNESCO (2008). Manual de Referencia de WinIDAMS (versión 1.3). París. http://portal.unesco.org/ci/en/files/25633/12155219637ManualR13S.pdf/ManualR13S.pdf
Zbiniew, N. (2001). Manual para el usuario del Winisis (versión 1.4). Ciudad de La Habana, editado y corregido por Raúl Torricella.
Recepción: 03 mayo 2018
Aprobación: 21 agosto 2018
Publicación: 31 octubre 2018